Natural dialogue corpus is a useful resource in sentiment analysis research. Scientists could make computer better understand human intension with it, but it is difficult to obtain. The ordinary way to build a corpus is to recruit experts or workers to label the collected conversion log. However, experts or workers may not truly understand the sentiment contained in the log. Furthermore, some feelings are hard to reconstruct after the moment passed. In this work, we propose a mixinitiative labeling approach which is designed to let people contribute labels during the conversation with minimum efforts.
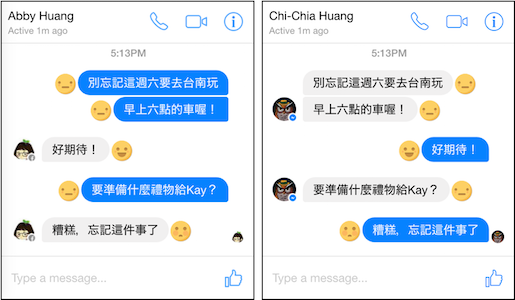
We design Chatmood system to let human and computer cooperate in building natural dialogue corpus. Computer is responsible to make rough emoticon predictions for every messages. On the other hand, human play a role of producing dialogue content and verifying the system gen- erate emoticons. In this system, human can tacitly agree the generated emoticons or make corrections if necessary.
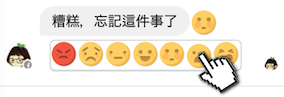
To make a correction, just click on the system generated emoticon, and then pick the appropriate emoticons in the expanded menu. A user can make corrections not only for his own emoticons, but also those belong to the opposite side. When a correction is made, it will be logged and delivered to the opposite side. The corrections could be used to improve emoticon predic- tion. With this system, we can collect two kinds of labels: the user-tacitly-agreed emoticons and corrections.
@misc{Huang:HCOMP15,
Author = {Huang, Chi-Chia and Huang, Yi-Ching and Hsu, Jane Yung-jen},
Date-Added = {2016-02-17 17:21:43 +0000},
Date-Modified = {2016-02-17 17:27:03 +0000},
Howpublished = {Work-in-Progress in Conference on Human Computation \& Crowdsourcing},
Location = {San Diego, California, USA},
Month = {November},
Url = {/people/pdf/Huang_HCOMP15.pdf},
Title = {Chatmood: A Mixed-initiative Labeling Approach to Building Natural Dialogue Corpus for Sentiment Analysis},
Year = {2015}}

